Database
De database is waar alle data wordt opgeslagen en in sommigen gevallen ook verwerkt. Deze data is opgedeeld in tabellen. Het hoofdstuk is zeer technisch van aard maar beschrijft naast de opzet van de data ook een oplossing voor de usability problemen wanneer we in alle optimisme te maken krijgen met een grote set oefeningen:
- Hoe maak ik de oefeningen vindbaar?
- Wat is een geschikte manier om oefeningen te beoordelen?
- Wat is een geschikte manier om oefeningen te sorteren?
De aanpak voor het ontwikkelen van de database laag was één van trial and error. De maatstaaf van succes was wanneer de gewenste informatie op een manier kon worden opgeslagen zodat ernaar gezocht kon worden.
PostgreSQL
PostgreSQL is een relationele database geschikt voor het opslaan van data met veel onderlinge relaties. Relaties zoals 'auteurs hebben blogposts', of 'blogpost heeft veel tags en een tag heeft veel blogposts'. In het domein van deze applicatie hebben we te maken met oefeningen, gebruikers, favorieten, beoordelingen, vragenlijsten, en allerlei relaties tussen deze tabellen.
Er is specifiek gekozen voor Postgres om gebruik te kunnen maken van vier interessante functionaliteiten.
JSONB: Dit is een kolom type dat het mogelijk maakt om aanvullende arbitraire structuren van data op te slaan. Dit is geïmplementeerd om de beschrijving van oefeningen dynamisch te maken.
Aggregatie filters: Voor een goede beoordeling en sortering strategie moeten veel berekeningen gedaan worden. Postgres biedt hiervoor een zeer fijne syntax.
Zoeken: Postgres biedt het kolom type TS_VECTOR. Deze maakt het mogelijk om zoekmachine functionaliteiten te implementeren binnen de database.
Ranges: Om duraties aan te geven, zoals bijvoorbeeld een oefening die 5 tot 15 minuten tijd kost biedt Postgres range kolom types. Deze maken het makkelijk om hier mee om te gaan.
Alternatieven zijn SQLite en MySQL.
SQLite is echter meer geschikt als een opslag formaat van desktop applicaties, of embedded applicaties zoals in de Internet of Things. (SQLite)
MySQL implementeerd minder van de SQL standaard en is minder snel in ontwikkeling en heeft daarom minder features. (Digitalocean)
Naast deze redenen heeft persoonlijke professionele ervaring bij Label A uitgewezen dat PostgreSQL goed werkt voor web applicaties met Python.
Datamodel

De database definieert ook een aantal procedures voor data verwerking:
- Het generen van semi-random id's.
- Het berekenen van beoordeling gemiddeldes.
- Het berekenen van een populariteitsmetriek.
- Het generen van lexemen voor de zoekmachine.
Wat volgt is een beschrijving van de rollen die deze tabellen en procedures hebben binnen het datamodel en wat ze mogelijk maken.
Gebruikers

Een user wordt gekenmerkt door een 'username', een 'email' en een 'password'. Waarvan de email niet verplicht is. Websites als reddit en hackernews doen dit ook. Een wachtwoord vergeten flow, of het versturen van nieuwsberichten is dus alleen mogelijk wanneer er een wel een email adres bekend is. Het password is uiteraard niet opgeslagen in leesbare vorm, hierover meer in het hoofdstuk over de server applicatie.
Heeft de volgende relaties:
- Is auteur van oefeningen.
- Heeft favoriete oefeningen.
- Heeft beoordelingen.
- Heeft ingevulde vragenlijsten.
Oefeningen
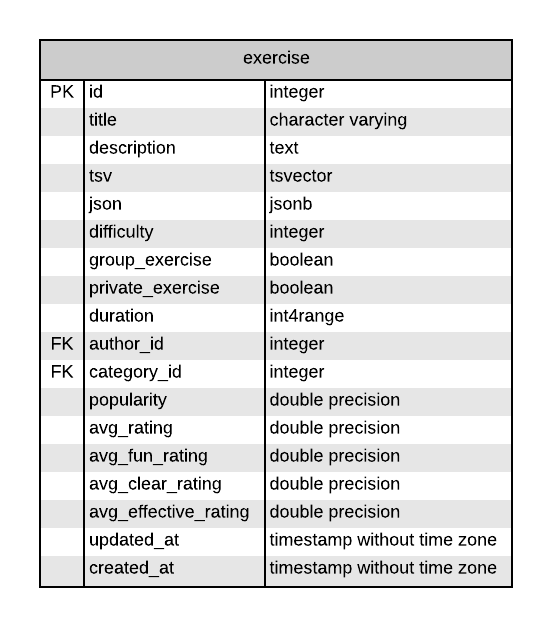
De exercise is de kern van de applicatie. Deze tabel is daarom het meest complex. De 'title', 'description' en 'category' spreken voor zich. Veel van de conclusies die zijn voortgekomen uit de focus group en gesprekken met de stakeholders zijn hier terug te vinden. Naast de velden die in het onderzoek zijn besproken zijn de volgende velden toegevoegd ter bevordering van de vindbaarheid.
- tsv: Het 'tsv' veld staat voor ts_vector. Dit is een data type waar een een text wordt opgebroken in lexemen, in ons geval de titel en bescrhrijving.
Een voorbeeld zal duidelijker zijn. Stel voor een oefening met een titel "Tellen op je hoofd" en een beschrijving "Wanneer je op je hoofd bent gaan staan, tel dan van 100 heel snel naar 0". Postgres zal dan de volgende tsvector genereren:
'0':20B '100':16B 'bent':10B 'gan':11B 'hel':17B 'hoofd':4A,9B
''snel':18B 'stan':12B 'tel':13B tell':1A 'wanner':5B.
De letters en cijfers bij de lexemen geven elk woord een score. Dit resulteert bij het zoeken in een ranklijst van zoek resultaten. De lexemen maken het mogelijk om een oefening terug te vinden met variaties op de woorden in de titel of beschrijving.
- popularity: Een ander veld dat essentieel is voor de vindbaarheid is de 'popularity'. De populariteits metriek is een alternatief voor het sorteren op gemiddelde beoordelingen. Zie hieronder voor een beschrijving van hoe dit precies werkt en hoe het het probleem van gemiddeldes oplost.
Heeft de volgende relaties:
- Is geschreven door een gebruiker.
- Is toegevoegd aan favorieten door gebruiker.
- Heeft beoordelingen.
Beoordeling

De rating legt een link tussen een gebruiker en een oefening, en elke gebruiker kan maar één beoordeling hebben per oefening. Het onderzoek heeft geleidt tot een samengestelde beoordeling bestaande uit scores voor leuk, duidelijk, effectief en gemiddelde van de drie op een schaal van 1 tot en met 5.
Heeft de volgende relaties:
- Is gegeven door een gebruiker.
- Beoordeeld een oefening.
Populariteit
Bij het toevoegen of aanpassen van een beoordeling aan een oefening wordt er door de database automatisch een gemiddelde berekend van alle beoordelingen. In een eerste iteratie was dit de manier om oefeningen te sorteren op populariteit. Het bleek echter al gauw inadequaat. Een oefening met één beoordeling van 5.0 heeft ook een gemiddelde van 5.0 en zal altijd boven een oefening staan met negen 5.0 beoordelingen en één van 1.0. Om hier iets aan de doen is onderzoek gedaan naar een manier om populariteit te kwantificeren.
Het artikel Bayesian ranking of items with up and downvotes or 5 star ratings van Jules Jacobs beschrijft de populariteit als een functie van:
- Een begin assumptie over de waarde van een item (een set neppe stemmen).
- De gegeven beoordelingen.
- Een toegekende waarde (utility) aan een beoordeling. De waarde van 1 ster, 2 sterren, etc.
Voor nadere uitleg over de assumpties en waardes is per mail contact opgenomen met de auteur van het artikel. Hij heeft aangeraden om te beginnen met simpele waardes. Deze kunnen bijgesteld worden naarmate de applicatie groeit.
Date: Sat, 30 Apr 2016 12:51:11 +0200
Subject: Re: bayesian ranking in posgresql
From: Jules Jacobs [email protected]
To: Mohammed Kareem [email protected]P.S. in practice you may want to use different utilities and pretend votes. I think that [0,1,2,3,4] and [1,1,1,1,1] would be a good starting point to experiment from.
Jules
P.S. in practice you may want to use different utilities pretend votes. I think that [0,1,2,3,4] and [1,1,1,1,1] would be a good starting point to experiment from.
De details van het algoritme zijn te vinden in de artikel.
Ter illustratie van het verschil met het nemen van gemiddeldes.
Een oefening met één beoordeling van 1.0, en negen keer 5.0 heeft een
populariteit van 3.06 en een gemiddelde van 4.6.
Een oefening met één beoordeling van 5.0 heeft een populariteit van
2.33 en een gemiddelde van 5.0.
Het algoritme is geïmplementeerd als een procedure in de database. Net als het gemiddelde wordt ook de populariteit bij elke beoordeling geüpdatet.
Conclusie
Om oefeningen te kunnen zoeken, sorteren en beoordelen moeten de menselijke ideeën hierover worden vertaald naar een datamodel die een oefening, beoordeling en gerelateerde informatie vertegenwoordigen in een digitaal systeem. In dit hoofdstuk is laten zien dat dit is gelukt met een flexibiliteit voor mogelijke toekomstige functionaliteiten.